NOAA maintains thousands of datasets of various kinds (remote sensing, in-situ, derived etc.) across multiple domains (climate, weather, ecology, etc.) consumed by a wide variety of users (scientists, engineers, urban planners, etc.), but discovering, accessing, and using these datasets remains a significant challenge. Recent developments in cloud-native geospatial technologies and standards have made geospatial data easier to access and manage now than ever before. Now the question is: can we go a step further and also make it trivial to query and analyze this data using modern large language models (LLMs)?
In this blog post, we present some highlights from our ongoing open-source work aimed at answering precisely these questions, as part of a NOAA-funded study. The goal is to build a natural-language interface that allows users to not only search for datasets (“show me datasets related to sea surface temperature”), but also extract arbitrary insights from them (“What are the trends in sea surface temperatures around near-coast gulf waters over the past several decades?”) and get factually-grounded answers derived from real data that are not only correct and comprehensive, but also include detailed provenance information so that users may verify them.
This is a deeply interesting problem that touches on areas such as cloud-native formats, multi-agent workflows, LLM evaluations, knowledge representation, programming language design, distributed computing, and user experience design. Here, we limit ourselves to sharing some highlights from the following aspects of our current approach:
- Analyzing data
- Finding the right dataset
- Orchestrating a multi-agent workflow
- Presenting the answers and steps in a way that users can verify
We note that the project is still ongoing and details are subject to change.
Data Analysis
Climate data is usually distributed as daily or monthly NetCDF files which can number in the tens of thousands or more for long-lived datasets. The modern cloud-native geospatial (CNG) stack provides powerful tools to handle such data:
- Virtual Zarr stores allow these disparate files to be consolidated into a single virtual dataset
- Xarray allows these virtual datasets to be transformed
- Dask allows these transformation to be applied to vast amounts of data in an efficient, distributed manner
What we are concerned with in our application is figuring out the right transformations to apply to these datasets to precisely answer any question that a user might ask. This is the kind of highly complex reasoning task that would have been impossible to perform with any kind of reliability in the past, but is the sort of thing that state-of-the-art LLMs have been getting increasingly better at.
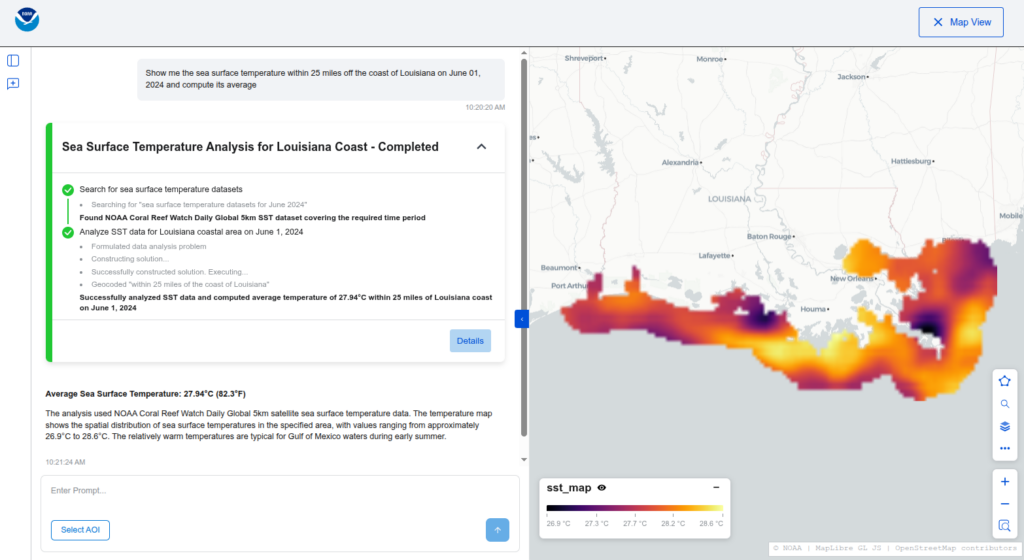
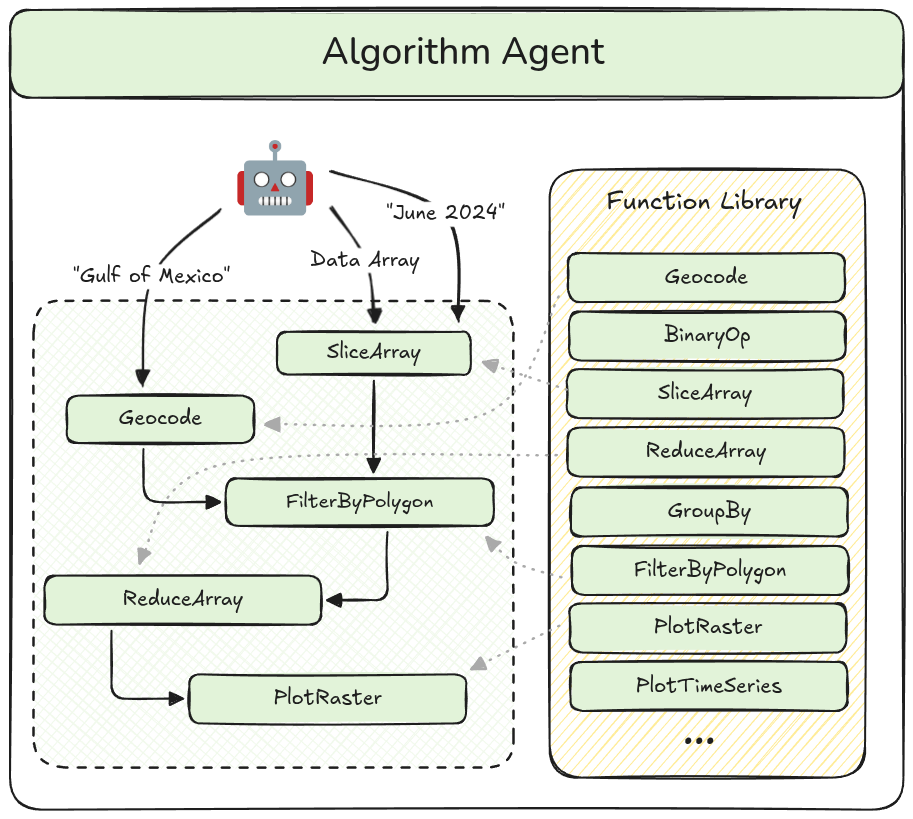
How exactly we use an LLM agent to solve such problems is an interesting question. Possible approaches range from generating and executing raw Python code to merely choosing between existing human-written algorithms for different kinds of problems. The approach that we have settled on for now is a compromise between the flexibility of the former and the reliability of the latter: for any given user query, we ask the “algorithm agent” (visualized below) to construct a bespoke algorithm by composing together pre-defined human-written functions. The output is a structured JSON object that we can validate in various ways, including applying static type checking, and then translate to Python code which is then executed on a Dask cluster.
Data Search
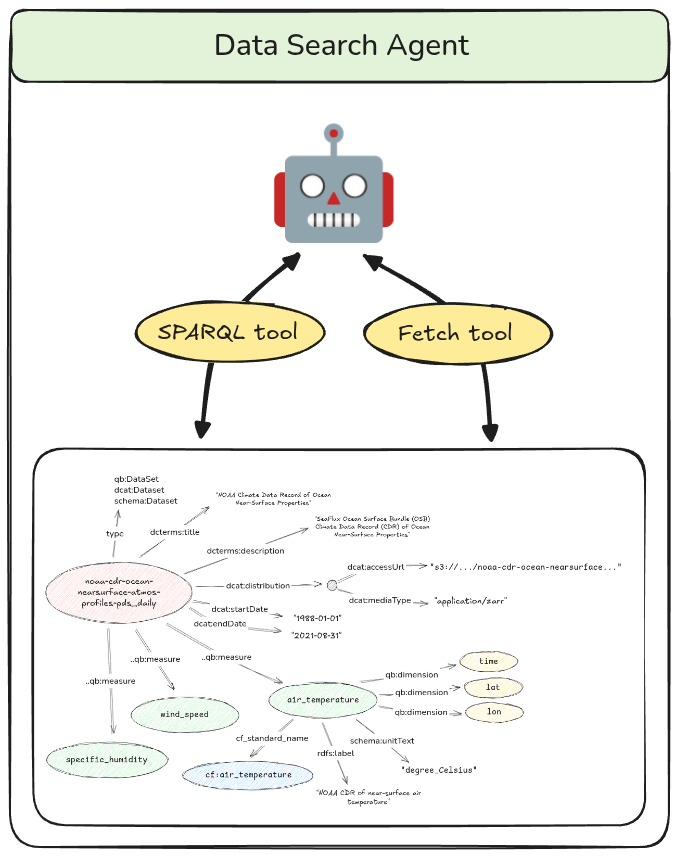
Before we analyze the data, as discussed above, we need to find the right dataset. This is not a simple matter because the users’ questions will usually not contain the actual name of the datasets or the variables within them. Furthermore, there might be multiple datasets that seem relevant to any given question. This suggests a need for intelligence at the search level, which is why we encapsulate the search functionality inside a “data search agent”. This agent queries a knowledge graph containing metadata for various climate datasets represented using standard scientific ontologies.
Orchestration
We organize our multi-agent workflow using an orchestrator pattern. The orchestration agent is the only agent that communicates directly with the user and delegates tasks to other agents via special tools. Using tools as the interface for agent-to-agent communication allows us to more precisely define its structure, and thus, validate it. It also forces the orchestration agent to translate potentially ambiguous user queries into precise inputs to the tool thus limiting the spread of these ambiguities into the rest of the workflow.
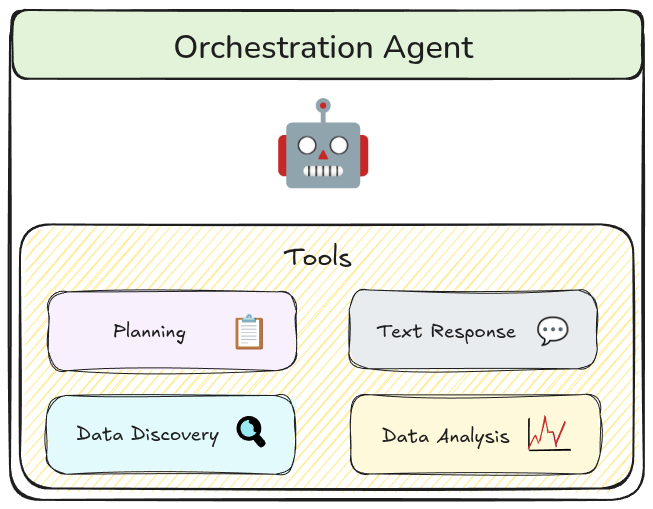
Presentation
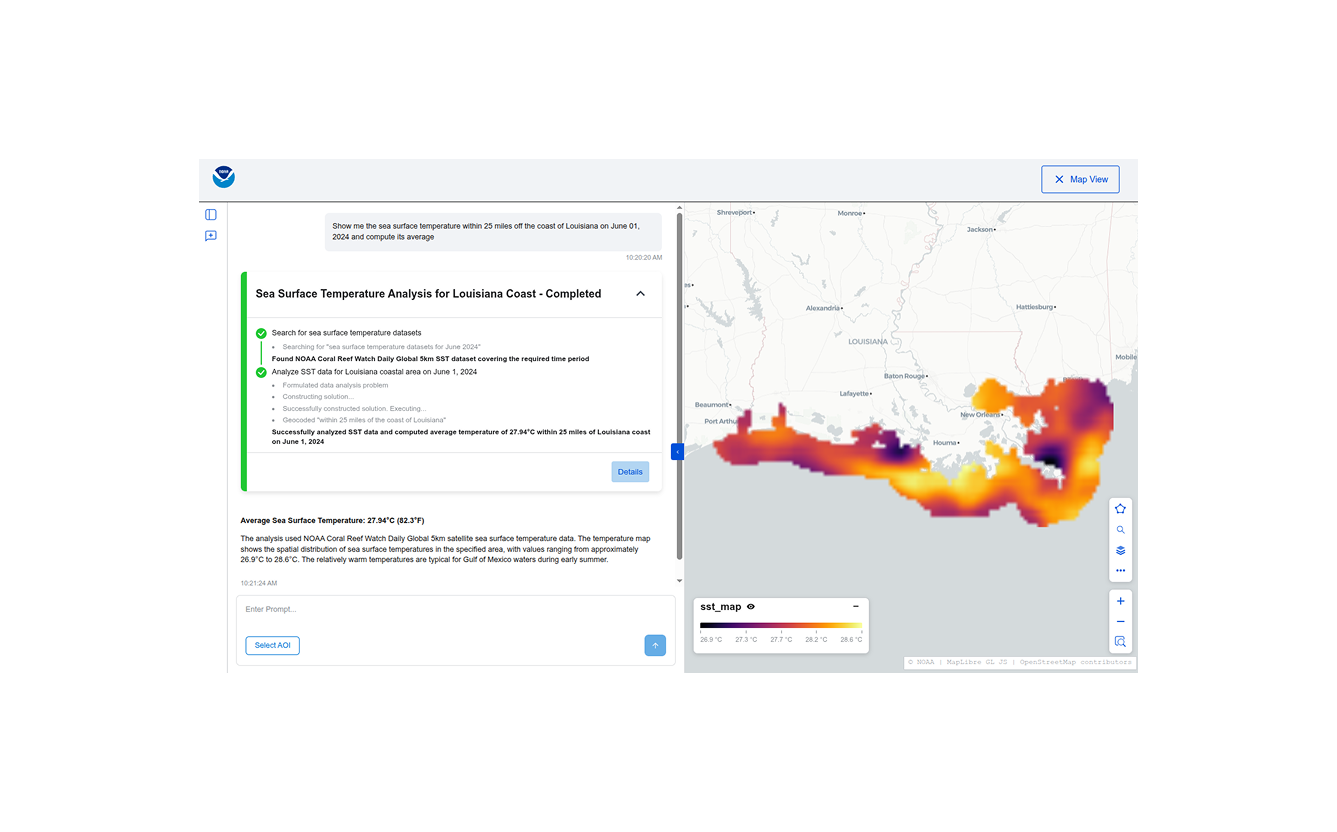
When dealing with complex agentic workflows, especially ones that purport to perform scientific analysis, it is important that all the steps performed be transparent and verifiable. To this end, we surface detailed progress updates and provenance information in the UI, including a pseudocode representation of the algorithm used.
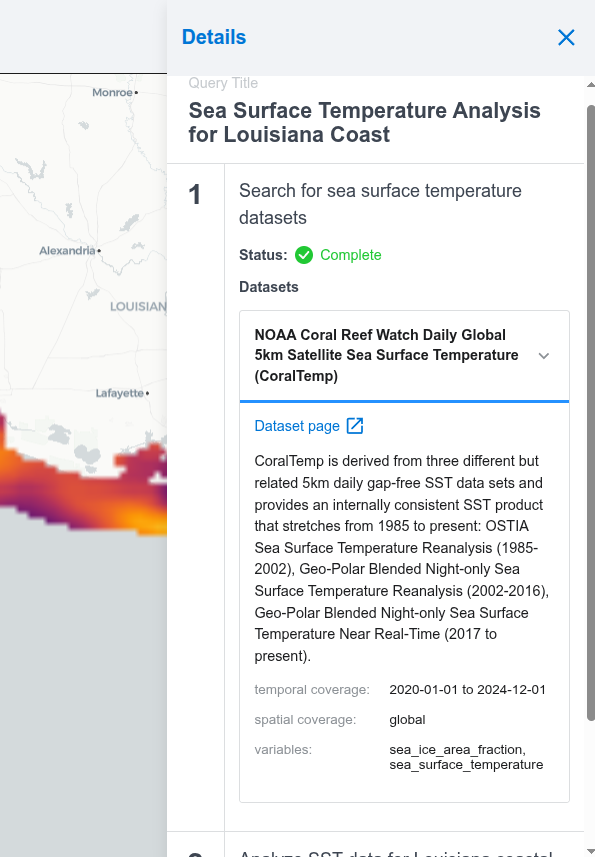

The UI surfaces detailed provenance information for the generated answers.
Big Picture and future development
There is a widespread recognition in the geospatial community of the potential of LLM-powered natural-language, conversational interfaces to accelerate data discovery and analysis, with multiple groups building demos similar to this one for various datasets. In many ways this can be seen as the logical culmination of the painstaking work on standards, data formats, and software tooling that the open source geospatial community has engaged in over many years. It is only with that groundwork in place that we can finally apply modern AI techniques effectively.
But this is also just the start. Now that we know this works, the incentive to “uplift” all datasets into analysis-ready, cloud-optimized formats is greater than ever before. EarthMover’s recently announced data marketplace is a step in this direction. Alongside this, on the AI front, an open question is how best to make these datasets discoverable for AI agents. Well-curated metadata will go a long way in enabling this. Relatedly, exposing datasets and capabilities through public MCP servers and tools will reduce siloing and enable really powerful new workflows.
If you’re interested in discussing this work, or learning more about querying and analyzing geospatial data more generally, we’d love to connect. Reach out to our team any time on our contact us page to share related work or discuss these ideas in greater depth.В
Acknowledgements
This work is a collaboration between Element 84 and TechTraverse as part of the NOAA-funded “Study to Determine Natural Language Processing Capabilities with the NCCF Open Knowledge Mesh” BAA. Project contributors include: Kendall Aubertot, Sean Malone, Jason Gilman, Evan McQuinn, and Steph Wall.
